Following the topic in this series, we should talk about the following factor to consider, breaking down Kubernetes applications development workflow into different stages: source code authoring, configuration authoring, packaging and deployment.
In kubernetes world, an application (or any component) is structurally composed of 3 different things: the container image(s), the deployment definitions and the configuration applied at every different deployment, as the same application can be deployed as different instances or in different logical environments. As we saw before, this can be referenced as the Application Physical View.
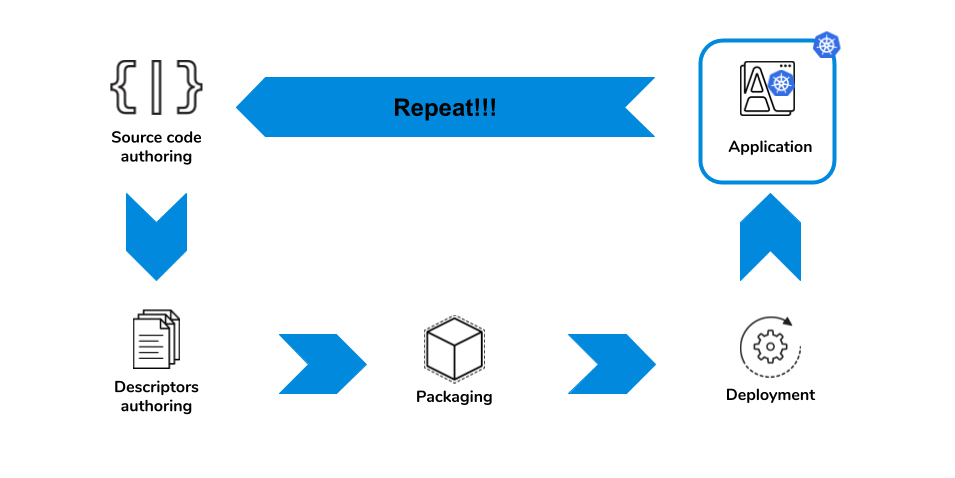
The application source code is authored, depending on the language can then be compiled, and finally packaged along with the application dependencies. This is the container image.
Defining a container image is not an easy task, as the biggest problem is that along with your application, you’re packaging the user space that your application will need to run. This is something that typical developers don’t know how to do well. Not only that, but this is also something that many operations team would not want developers to do.
For this reason, there’s a set of tools that abstract away the process of building your source code into a container image. A plain Dockerfile is the simplest form, but then there are more advanced tools, like buildpacks or s2i that will take this problem away from the developer.
Once we have this application image created, we need to define how it will be deployed on the platform. Kubernetes provides many different controllers to run containers in different ways, stateless, stateful, daemons and jobs.
But there’s many other things that applications need in order to be consumable in a platform like Kubernetes. Services, Ingresses, PersistenceVolumes,… All of them have their own resource definitions that can be complex and long. To simplify how users would have to deal with all these multiple resource definitions a common set of tools have emerged that provides a means to define all these resources at once. Tools like Helm, Kustomize, Ytt, Cue, Tanka and many more are amongst the most used ones.
Some of these tools will also take the responsibility of applying these definitions to a Kubernetes cluster, but we can find more specialized tools that can do the task very well, like Kapp.
A final set of tools can help developers abstract some of these stages away. Why? Because most of us don’t want to deal with the physical view of the application on Kubernetes. We just want to create our application and work with some expert on the platform that will help us with all that boilerplate for us. There are some interesting tools in this space like skaffold, tilt, devspace and others.
We need to keep reminding ourselves that Kubernetes is not an easy tool for developers, and despite many of us knowing some of these tools, we would have preferred not to, but sadly there’s not yet one tool that can abstract Kubernetes away from developers good enough.
In the coming weeks, I’ll be posting evaluations and comments on some of these tools as I progress the idea of what an ideal world for developers could be. But before that, we need to wait for the final article on this series, coming soon.